
In this POC we will cover, how to parse a PDF in Pega using EForm.
Demo Video:
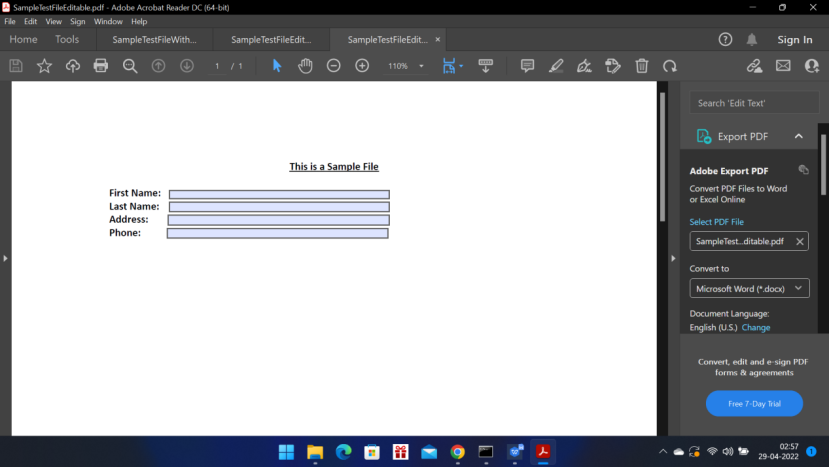
- Prerequisite: Create a PDF file with Editable fields.
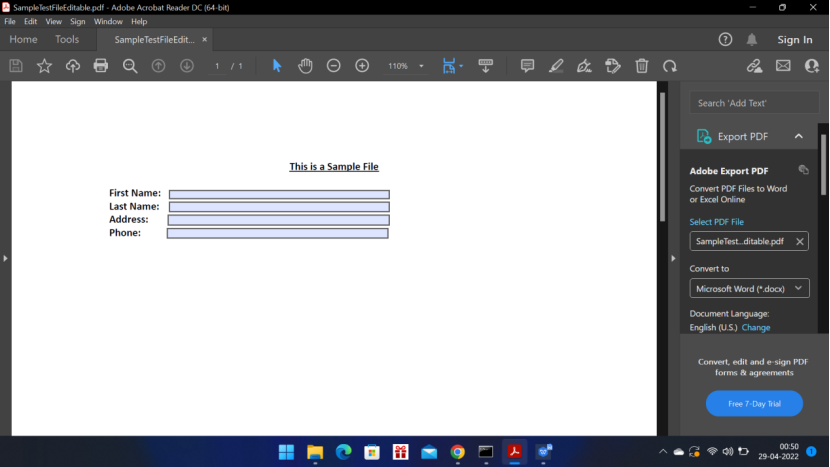
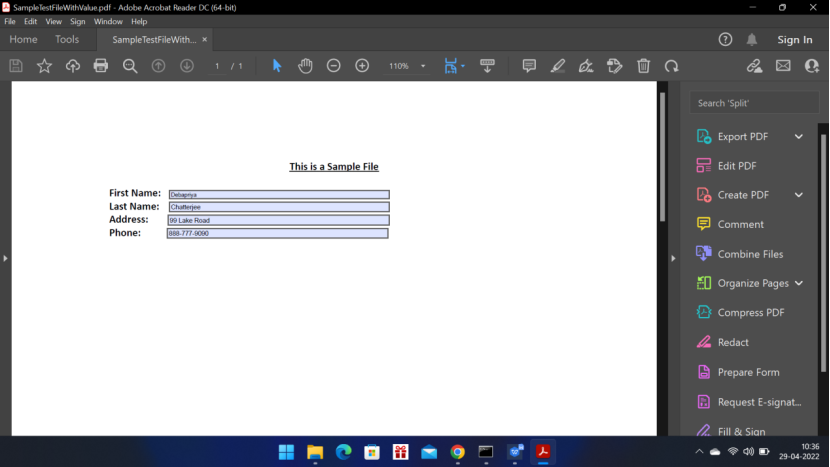
Sample File:
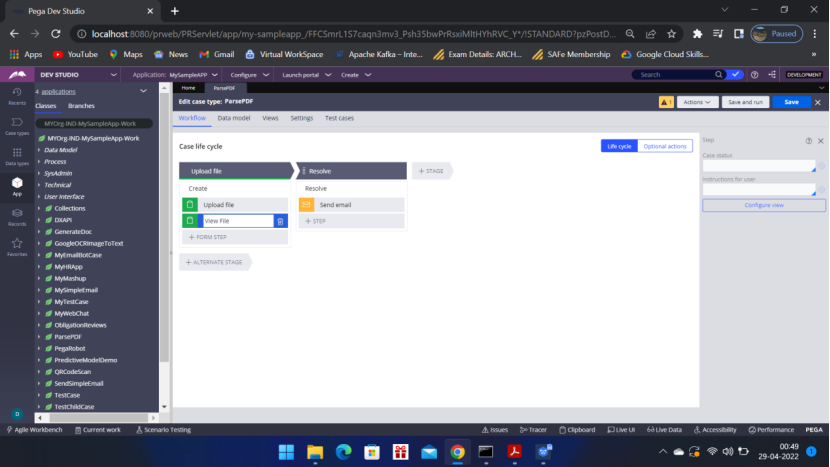
Create a Case Type
Create a SampleTestFileEditable PDF file using online tool. It should be editable PDF file.
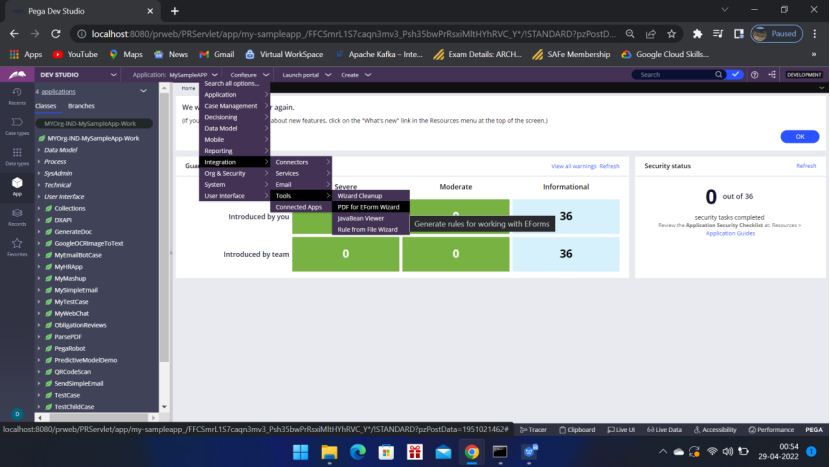
Now go to Dev Studio — Configure
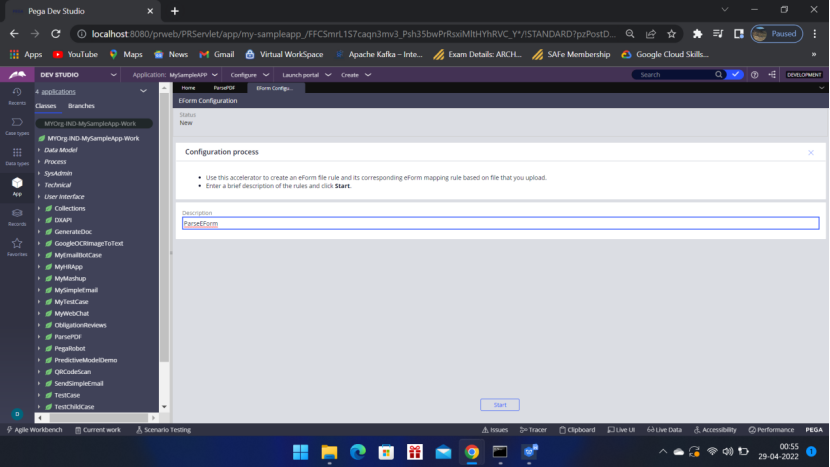
Click Start
Next screen enter the class of the case type — MYOrg-IND-MySampleApp-Work-ParsePDF
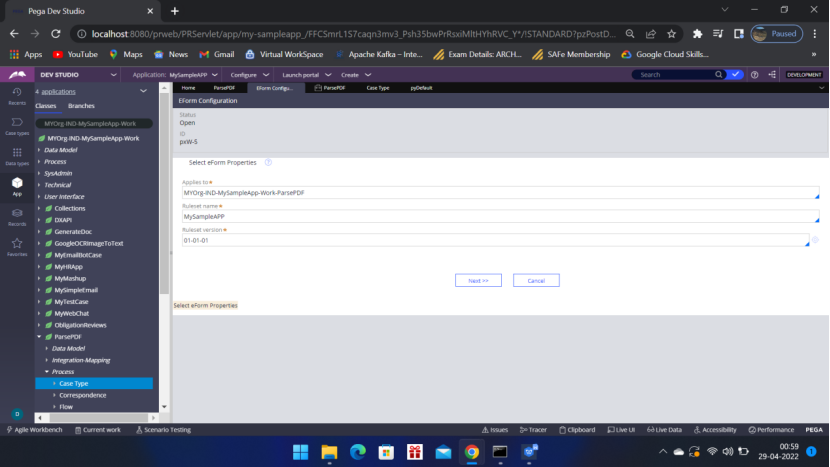
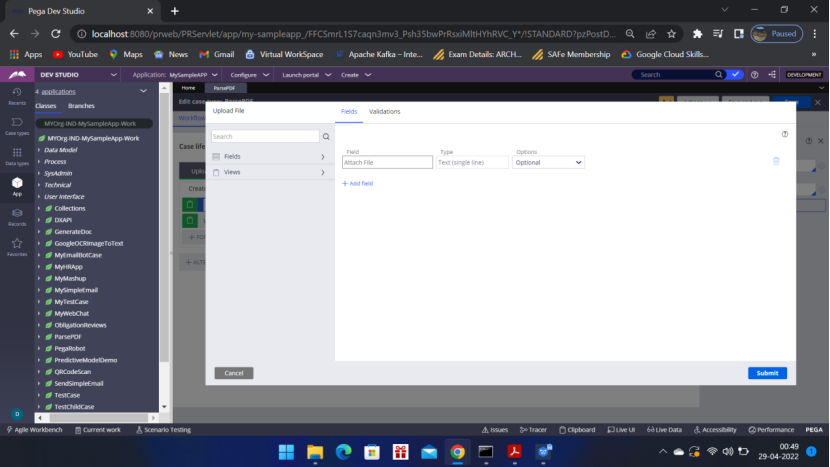
Click Next to upload the sample editable pdf file
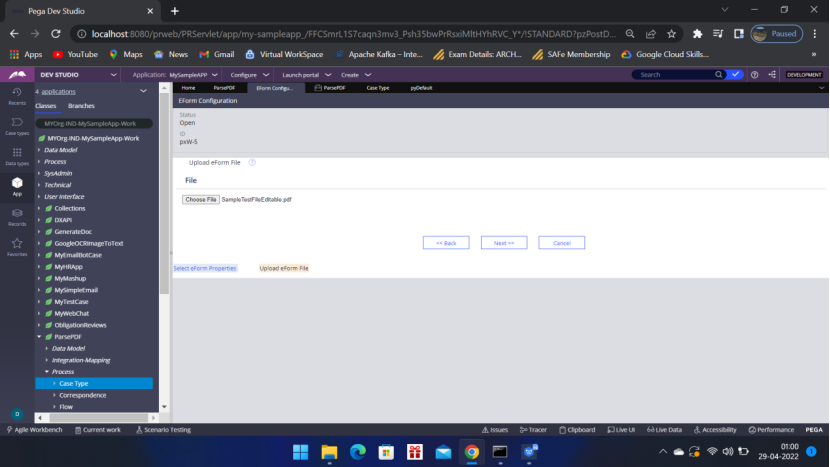
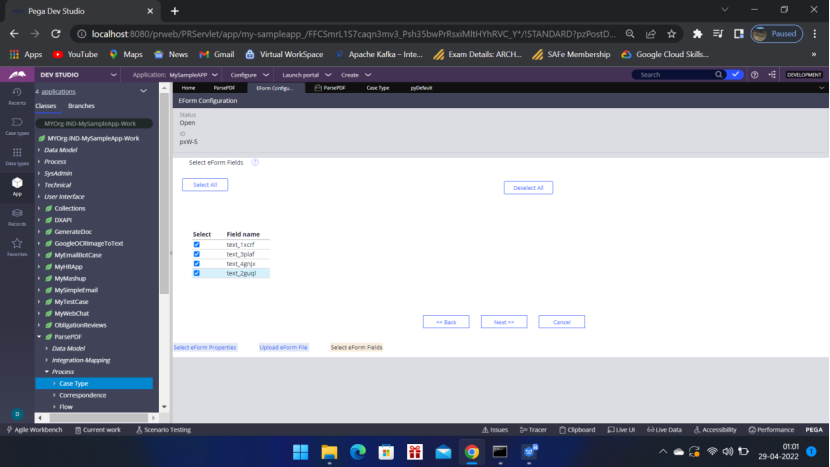
Click Next
Click Next
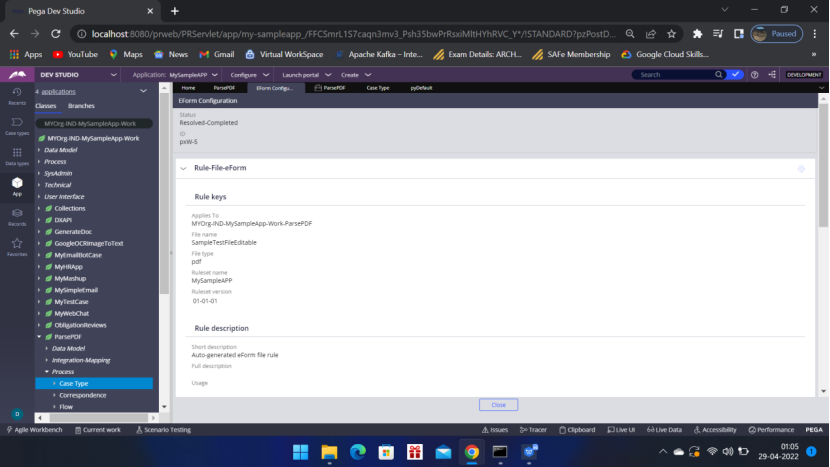
Resolved-Completed.
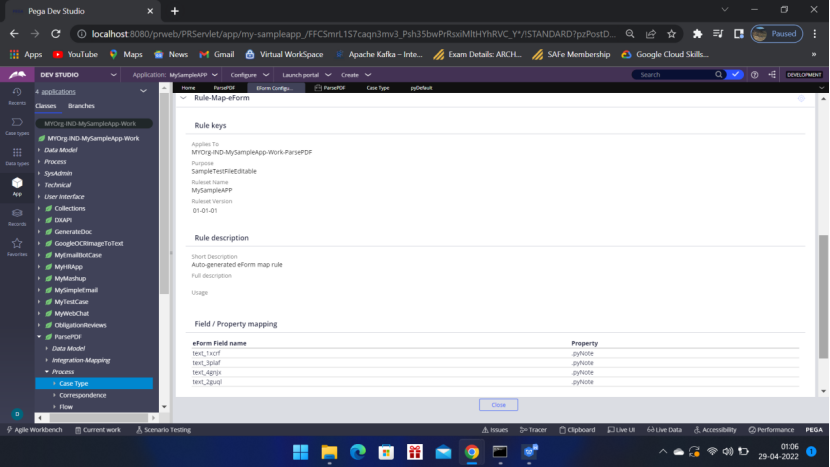
Click Close.
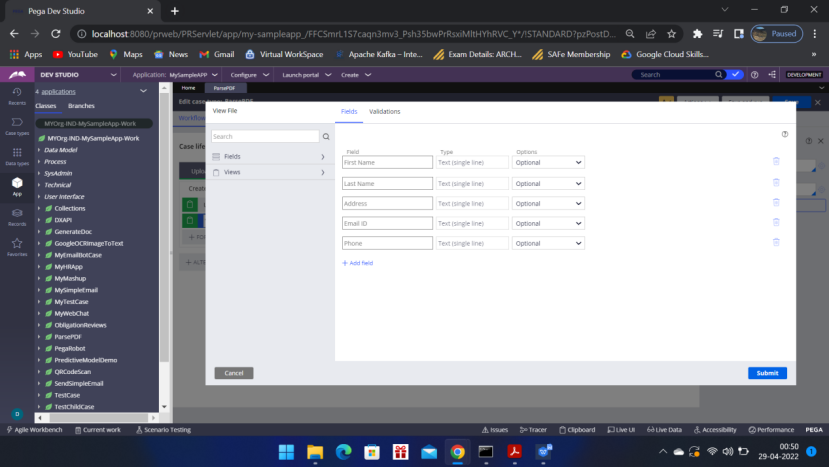
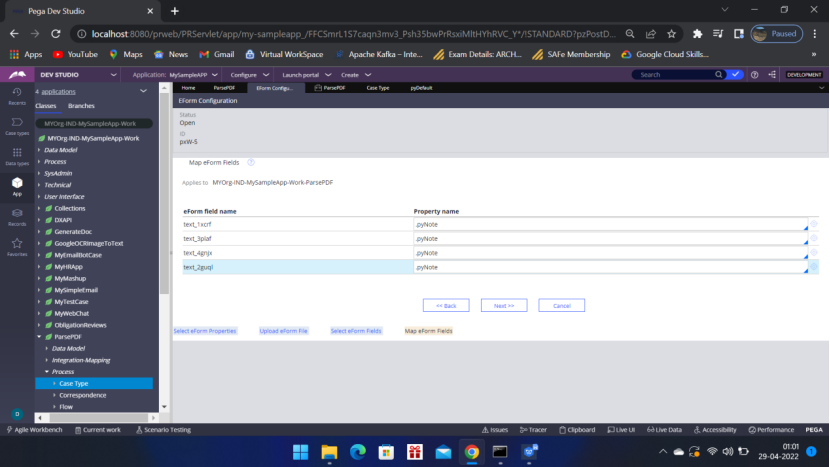
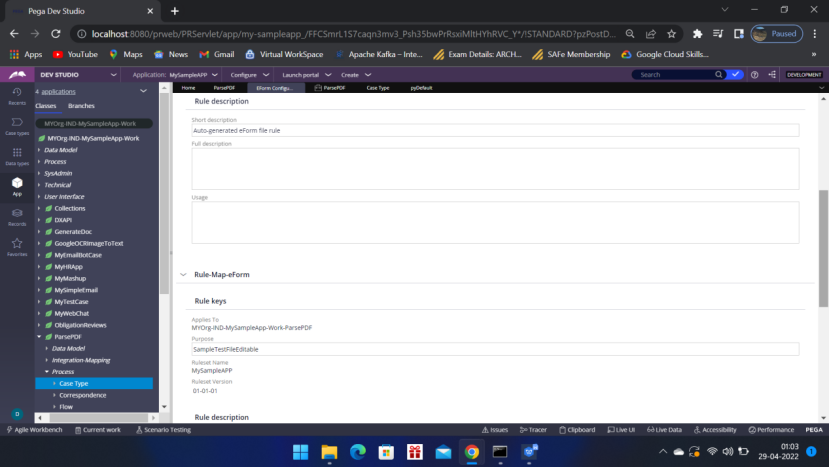
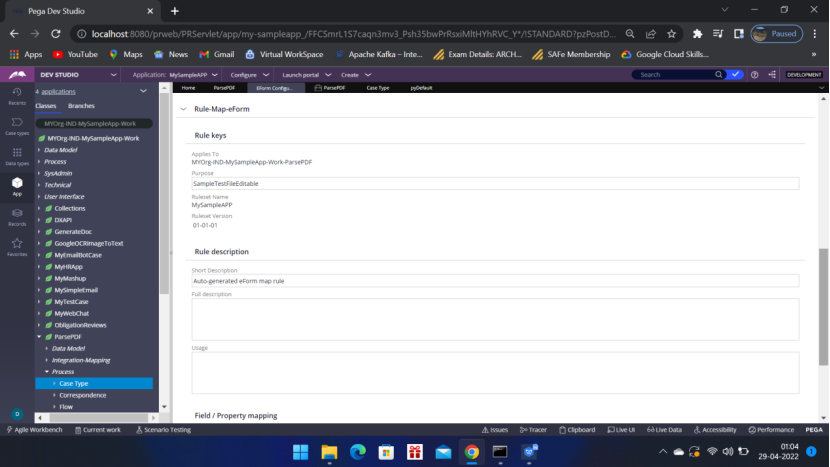
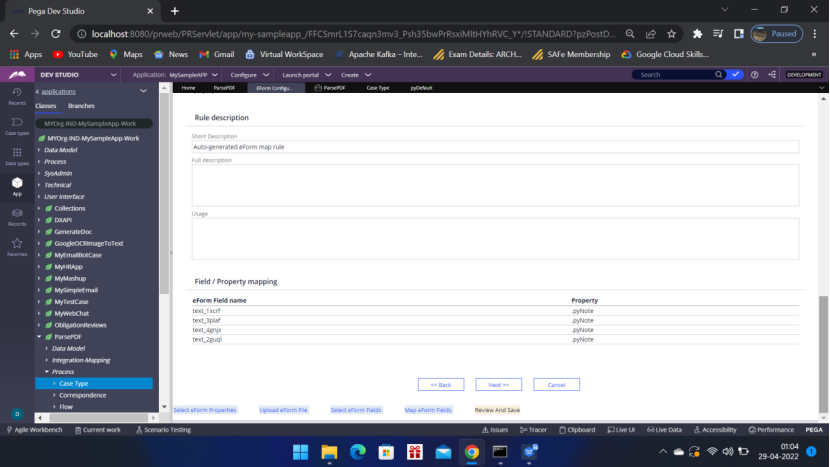
Now come to App — Open – ParsePDF – Integration-Mapping — EForm File, Map eForm have been generated.
Open the Map eForm rule to Map the properties to the clipboard. You can,
define the pyWorkPage in Pages and classes and use it to map the properties.
OR you can directly map the properties.
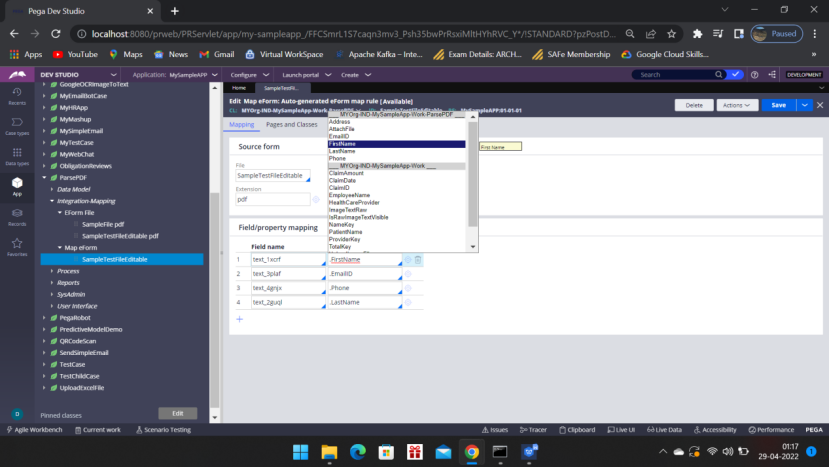
Now Create the Activity ParsePDFActivity– Records – Technical – Activity
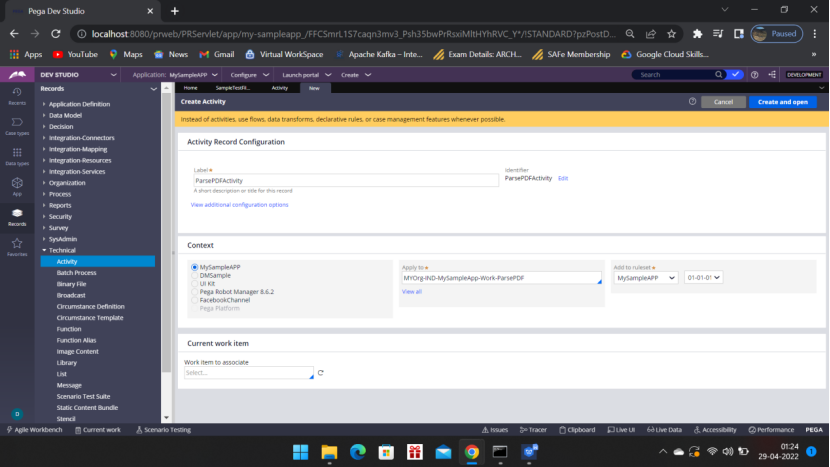
Add Parameters
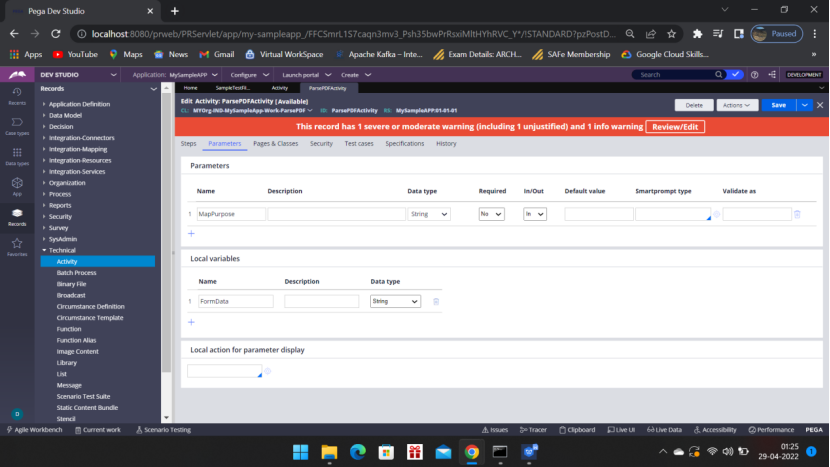
Pages & Classes
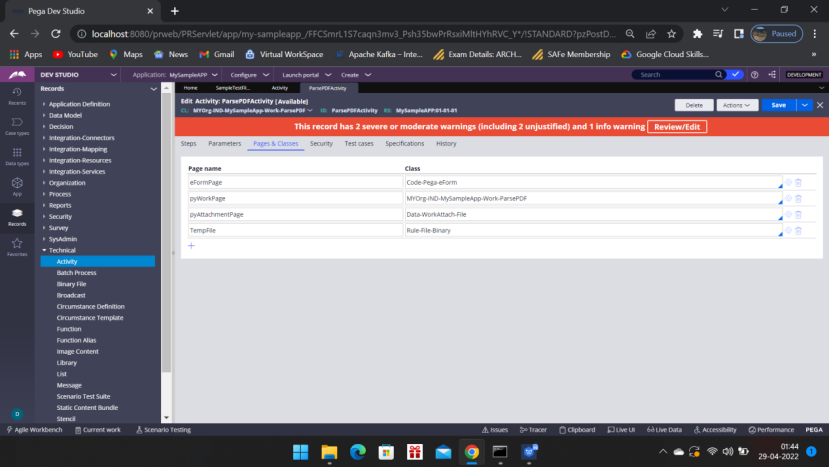
Activity Steps :
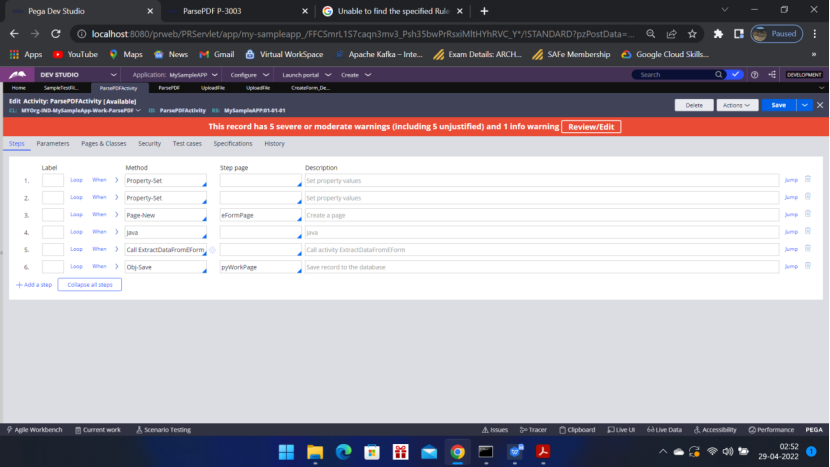
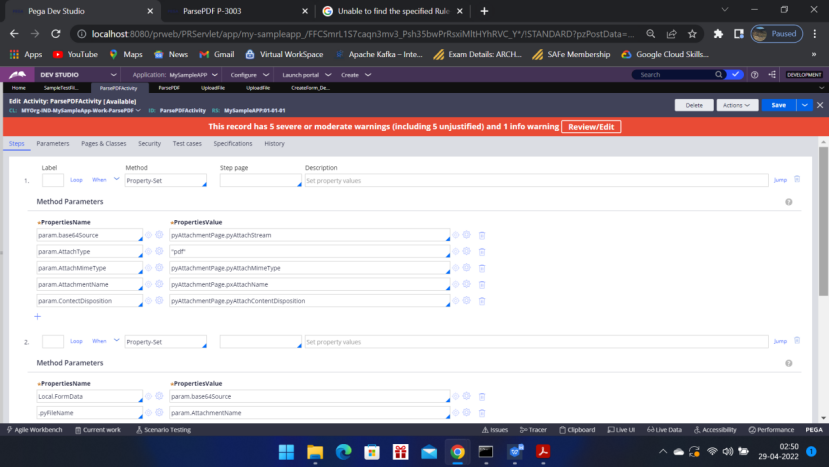
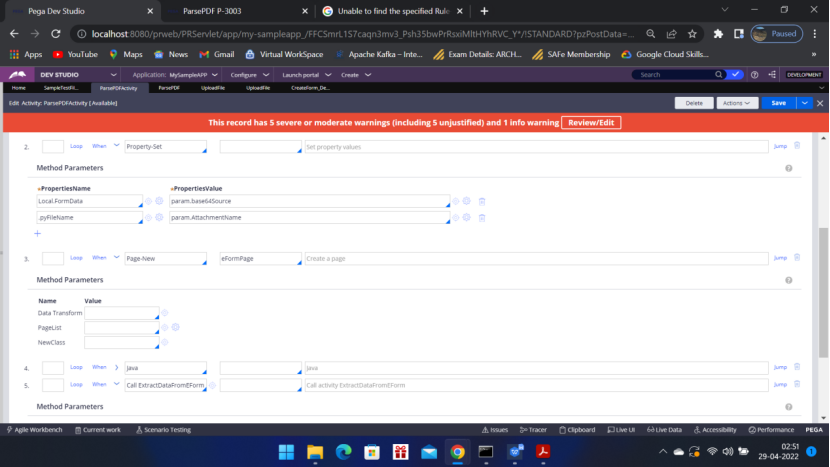
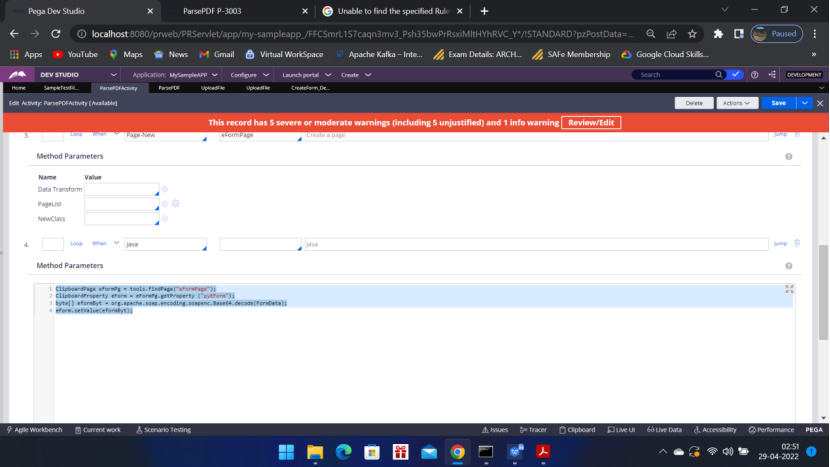
ClipboardPage eFormPg = tools.findPage(“eFormPage”);
ClipboardProperty eForm = eFormPg.getProperty (“pyEForm”);
byte[] eformByt = org.apache.soap.encoding.soapenc.Base64.decode(FormData);
eForm.setValue(eformByt);
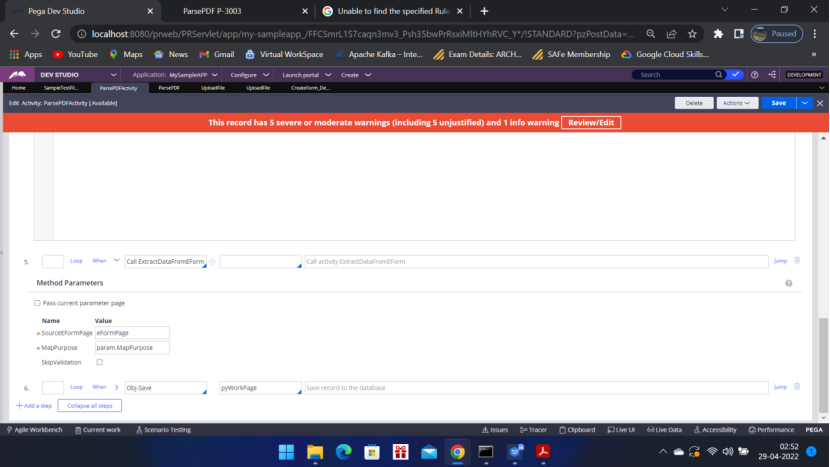
Go to the Case type — Flow – Flow Action — Call the activity
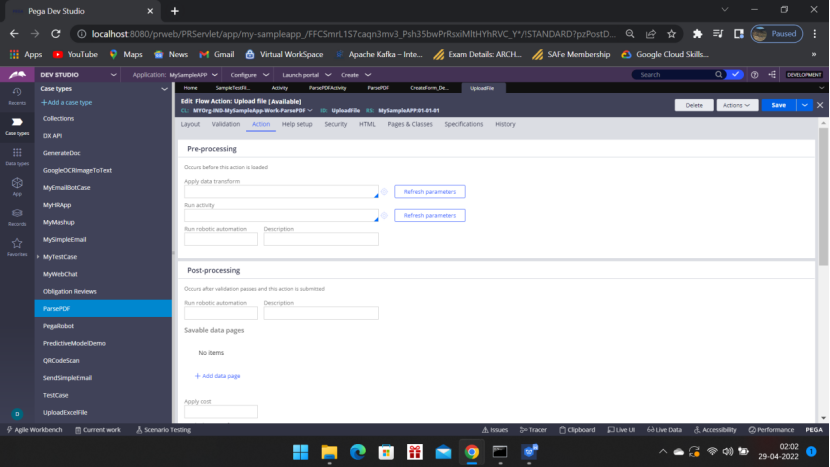
Scroll down
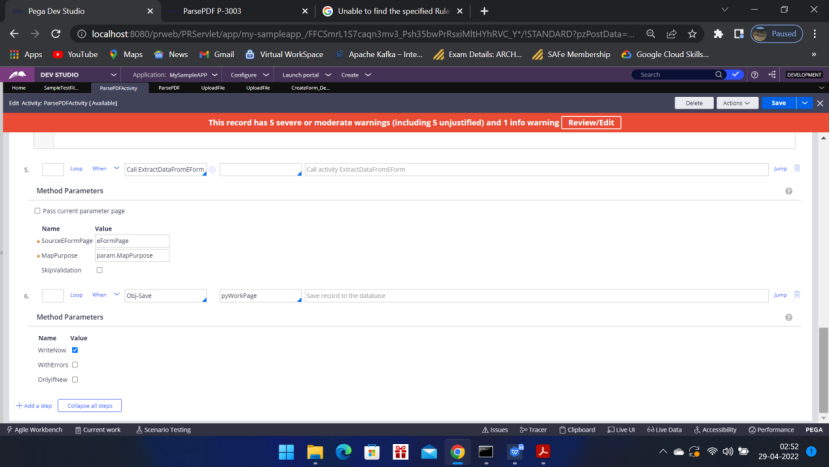
Under Post Processing – Post Processing Activity – Run Activity
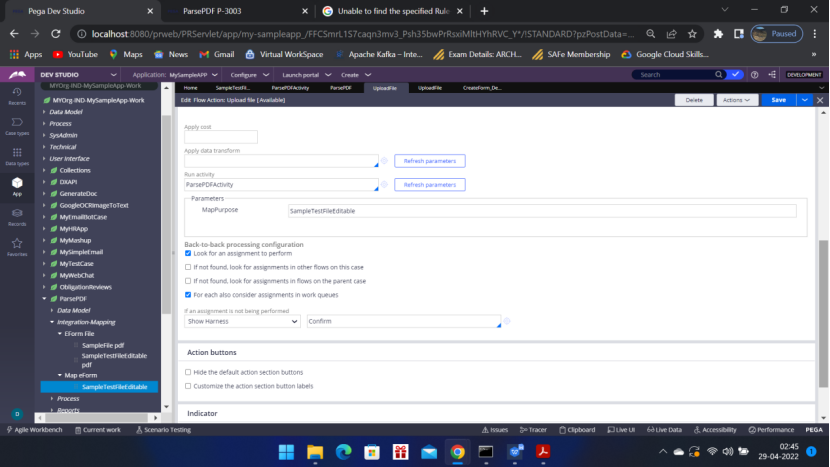
Call ParsePDFActivity — MapPurpose = Map eForm = ID of eForm map rule SampleTestFileEditable
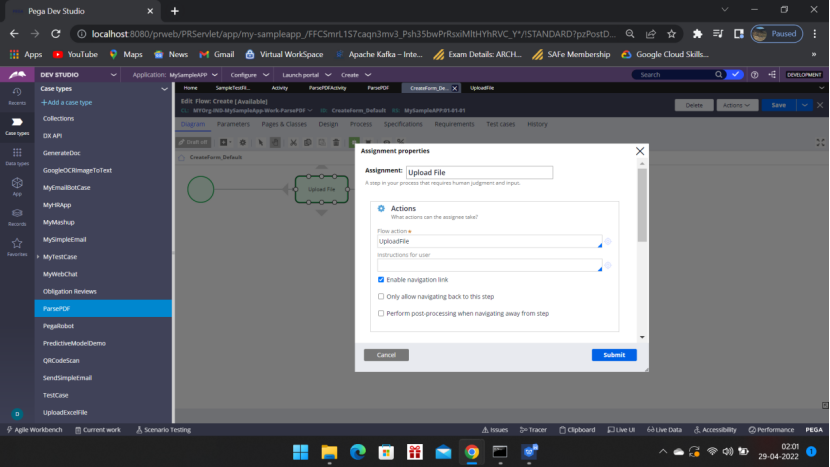
Now Go to the flow action — open the section
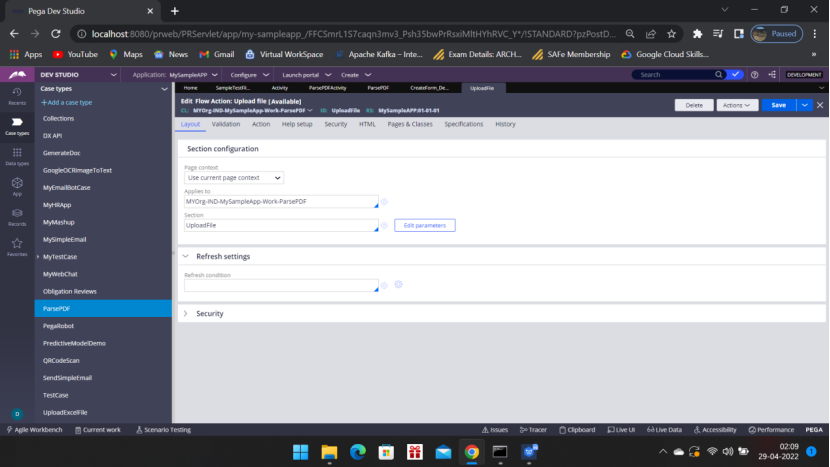
Convert to Full screen editor
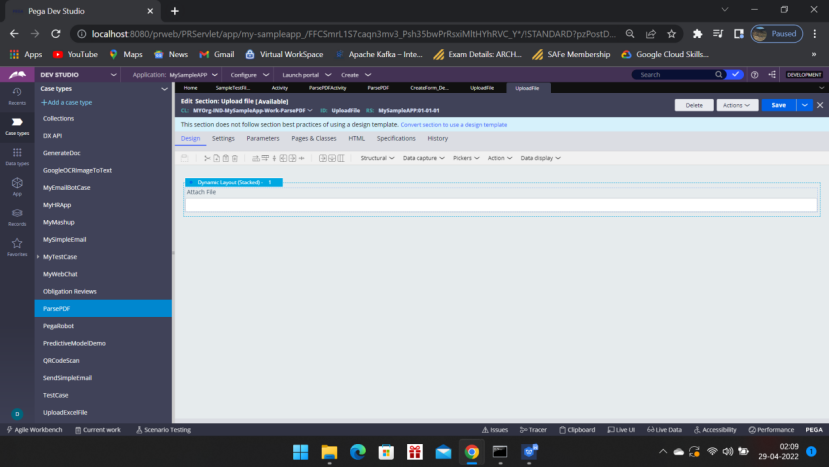
Click the gear icon
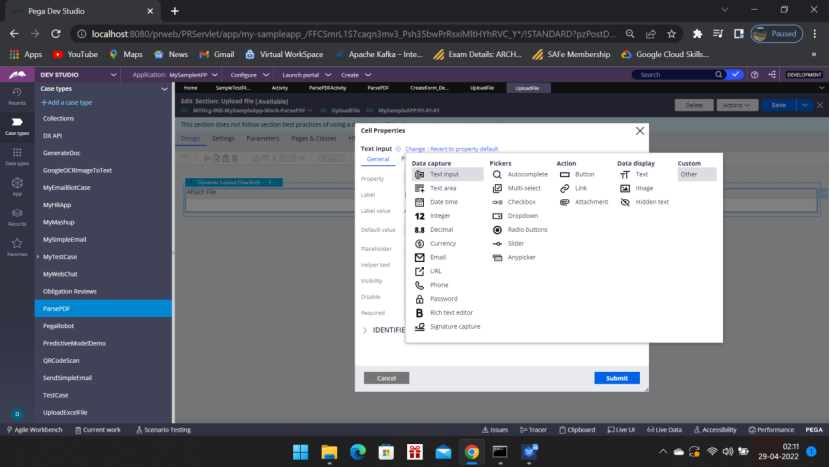
Click the Change link beside Text input – Custom – Other
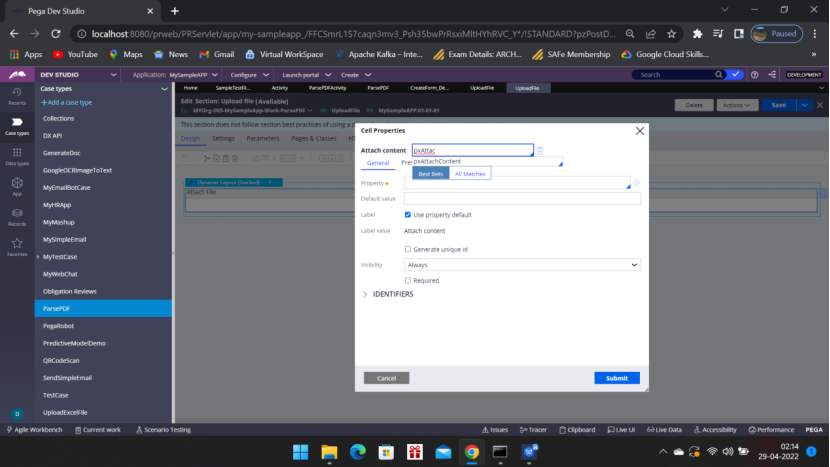
Type – pxAttachContent
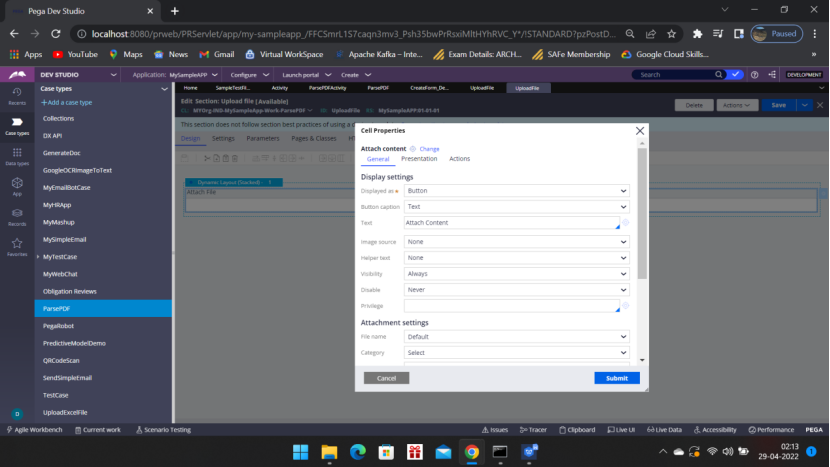
Run the Case Type
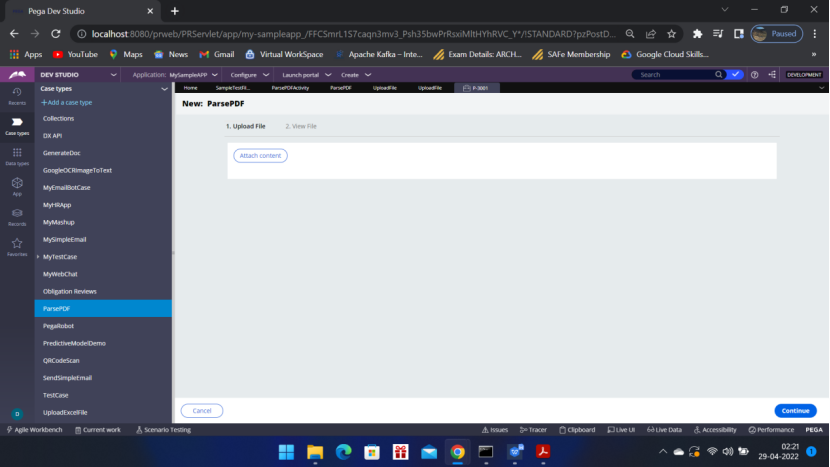
Sample file::
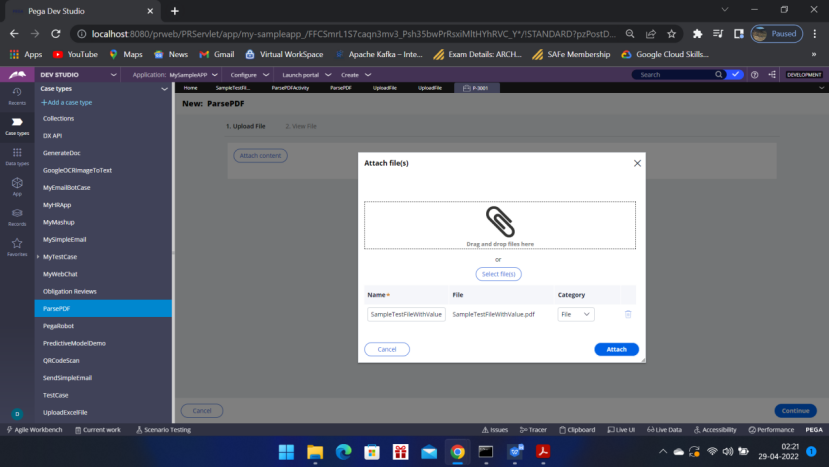
Upload the sample file — by filling the form with Data
Click Continue… Data will be available on the Pega screen— So the PDF file is successfully parsed.
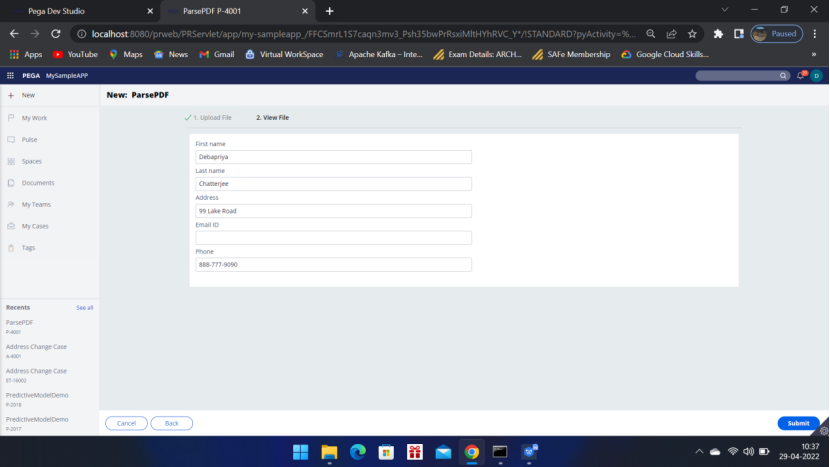
Now you can use this data in Pega for further processing and even you can change the data and generate a updated PDF file.
This is how we parse PDF file in Pega. I have already posted another POC, how to parse Excel File.
Hope you have liked the article. Please let me know your inputs in the comment.
Happy Learning!! 🙂
It was well explained. Please add step comments for better understanding for us.
Thank you Shivaprasad for the feedback. Will follow the same going forward.